Context
My talk at EuroPython 2021 was finally uploaded to YouTube. I got really excited about this, so I decided to share it on Twitter:
🚨📢 The recording 📽 of my @EuroPython 2021 talk has been uploaded to YouTube!
— Rodrigo 🐍📝 (@mathsppblog) September 29, 2021
In it, I walk you through the refactoring of a function, introducing many Python features.
Go watch it, and let me know if you find the Easter egg! 🥚 No one has, yet!https://t.co/L3acpxN3mI
In my talk, I walk you through successive refactors of a piece of “bad” Python code, until you reach a “better” piece of Python code. The talk follows closely the “bite-sized refactoring” Pydont'.
In the talk, I started with this code:
def myfunc(a):
empty=[]
for i in range(len(a)):
if i%2==0:
empty.append(a[i].upper())
else:
empty.append(a[i].lower())
return "".join(empty)
## ---
>>> myfunc("Hello, world!")
'HeLlO, wOrLd!'
>>> myfunc("Spongebob.")
'SpOnGeBoB.'And refactored it up until this point:
def alternate_casing(text):
return "".join([
char.lower() if idx % 2 else char.upper()
for idx, char in enumerate(text)
]).join
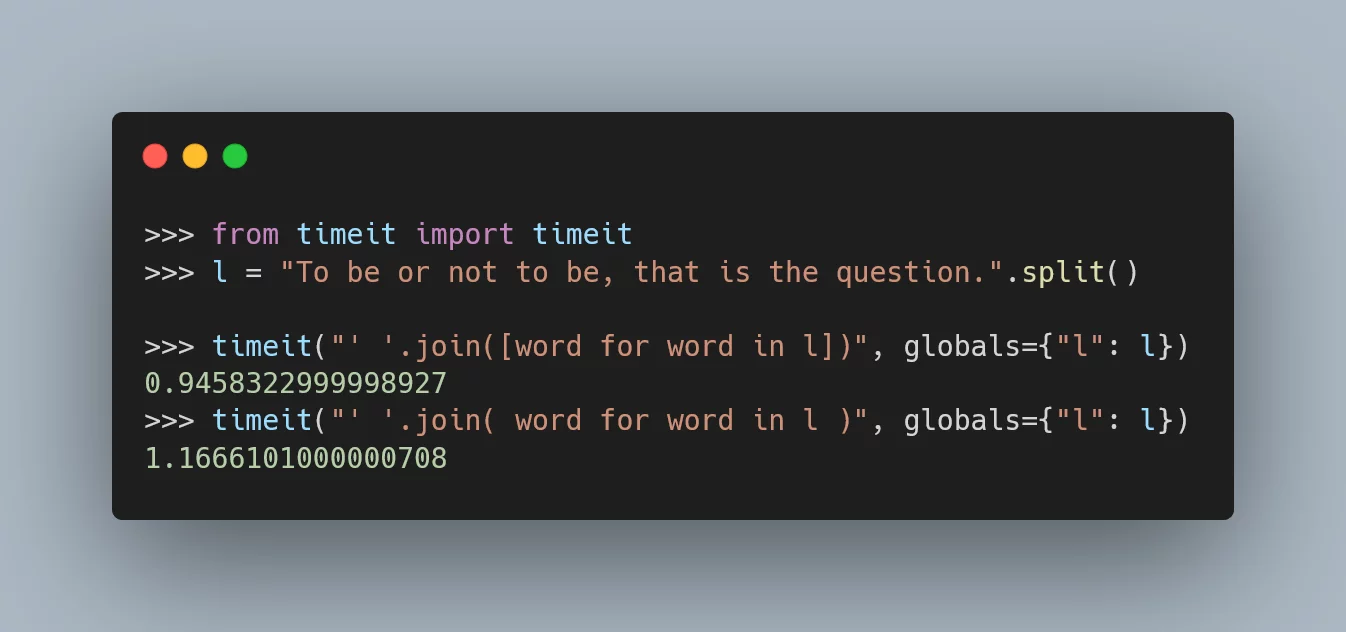
In a feedback tweet, someone said that I could've removed the [] of the list comprehension.
That would, instead, define a generator expression,
that should even be faster.
Thankfully, I was prepared for that: before the talk, I checked the performance of both alternatives, and found out that the generator expression was not faster.
That surprised me, because I was under the impression that generator expressions tend to be faster that list comprehensions, but the data in front of me didn't lie... And so, I didn't change the list comprehension into a generator expression in the talk...
But why is the generator expression slower?
As it turns out, the .join method is a two-pass algorithm!
At least, according to a tweet that was quoted to me:
This is incorrect — due to the implementation of str.join, the list comprehension is faster (annoyingly) https://t.co/gOdJm9hrd0
— Alex Waygood (@AlexWaygood) September 29, 2021
Sadly, I haven't been able to verify this yet.
However, it does make some sense:
if .join really is a two-pass algorithm, then generator expressions hurt us,
because generators can only be traversed once.
Therefore, we need to do something before .join can actually start its work.
Peeking at the source code for .join will probably reveal this...
I'm a bit sleepy, but I'll interrupt typing right now to take a quick peek at the source, see if I can find this code.
[Me browsing through Python's source code.]
Ok, I think I found it 🎉🎉!
In Python's GitHub repo, there's an Objects folder that contains a stringlib
that has a join.h file.
Opening it, you can see that there are two for loops over the data.
In the exact commit I looked at, at the beginning of the 30th of September of 2021,
those two for loops start on lines 61 and 125 or 133,
depending on some condition.
Cool, we checked that .join is indeed a two-pass algorithm!
That's it for now! Stay tuned and I'll see you around!
Become the smartest Python 🐍 developer in the room 🚀
Every Monday, you'll get a Python deep dive that unpacks a topic with analogies, diagrams, and code examples so you can write clearer, faster, and more idiomatic code.